Refactoring the Law: Reformulating Legal Ontologies
Copyright © 2005-2006 Garret Wilson
University of San Francisco School of Law
Juris Doctor Writing Requirement, Submitted 2006-03-16
Alongside Justice Holmes' oft-cited legal history, The Common Law,1 one of the classic explanations of the logical processes behind the evolution of the British/American legal system is Edward Levi's An Introduction to Legal Reasoning. There Levi describes the process of precedence as being divided into three phases: First, a legal concept is built up as cases are compared. Later the concept becomes fixed, although individual instances may be classified within or without that concept. During the third phase, disparate fact patterns cause the legal concept to break down, forcing the creation of new legal concepts.2
The legal concept Levi uses as his case in point is as amusing as it is pedagogical. Originally if a third party was injured by a seller's wares, the seller was not held liable if the third party had not purchased the item directly from the seller. Around 1851 courts began to allow exceptions to this rule if the item in question could be considered inherently dangerous.
3 By the turn of the 1900s the courts had categorized as dangerous in themselves
a loaded gun, mislabeled poison, defective hair wash, scaffolds, a defective coffee urn, and a defective aerated bottle; while categorizing as not dangerous
a defective carriage, a bursting lamp, a defective balance wheel on a circular saw, and a defective boiler.4
In MacPherson v. Buick in 1916, the courts were asked whether the Buick Motor Company should be liable because of an automobile that had collapsed because of a defective wheel, injuring a third party.5 The courts encountered a dilemma: is an automobile more similar to a locomotive, as the plaintiff urged, and therefore inherently dangerous, or more similar to a carriage, which the courts had held not to be inherently dangerous?6 The breaking point had been reached; and the courts held that a simple dichotomy based upon dangerousness was too rigid7 and even unnatural.
8 More recently, the group of legal experts which has written the Restatement of Torts has abandoned altogether the concept of inherent dangerousness
and instead focused on whether the item was defective.9
The problem here is not merely that human languages exhibit what Hart refers to as open texture,
10 or uncertainty on borderline cases within general classifications.11 The barrier to long-lasting legal rules is the more fundamental one that the classification schemes themselves are inevitably short-sighted and must eventually be recast as they are applied to more disparate fact patterns. As the American philosopher Alfred Korzybski12 nicely put it, The map is not the territory.
In setting down a set of rules, the law creates classification schemes13 that purport to describe the world in order to consistently effect desired outcomes, but because the schemes are separate from the world they describe they are inevitably inaccurate. These systems of categories or classes representing legal subject areas can never be immutable:
One might be tempted to conclude that [precedent], once developed, can be reused or extended simply by combining components of existing classes in different ways …. Often, however, [precedent] cannot be reused without first being restructur[ed]. There are several reasons for this:
- When developing [precedent], it is difficult to determine a priori what classes embody the important concepts for that [subject area] and how they interrelate. Experience has shown that a useful taxonomy of classes is discovered through an iterative process of exploration. As an understanding of the [subject area] improves, the system often needs to be restructured and the abstractions embodied in existing classes often need to be changed.
- Even after [precedent] has matured through several iterations, sweeping structural changes might still be necessary. The [precedent] must operate in an environment that is constantly changing, and the [precedent] must satisfy [public] needs that are constantly changing as well.
- When attempts are made to reuse [precedent] across [cases], new issues arise. A system may need to be partitioned differently, due to organizational and other factors, in order for a new [case] to reuse it. Thus, some structuring may be needed to effect reuse. …14
Classification systems are essentially conceptual models of the real world. With a certain set of symbols (words) to which are attached commonly recognized semantics (definitions), model-builders attempt to create abstract frameworks which will prescribe correct outcomes when presented with as-yet unknown fact patterns. Broadly speaking, model building can occur using one of two methods: from the top-down, striving to encompass every possible fact permutation within a complete, self-consistent framework; or from the bottom up, creating smaller, more localized categorizations that, while perhaps eventually coming in conflict with other localized models, are characterized by being quicker to implement, more specific to the problem, and more flexible to being changed in light of new experiences.
The preceding paragraph would not seem at all out of place in a computer software engineering journal, and for good reason: a computer software architect constantly uses these same terms to describe the process of creating abstract models of the world using computer programming languages such as Java and C++. The purpose of these software models, their limitations, and their need for later adjustments look suspiciously like those used by the legal community. In fact, the above quoted list of factors necessitating changes in common law systems of categories did not address the law at all in its original form—the list was taken from a landmark thesis, Refactoring Object-Oriented Frameworks, describing the evolution of models in object-oriented software. Only the terms projects,
software,
application,
and user,
have been replaced with cases,
precedent,
subject area,
and public,
respectively.
Leading computer software architects recognize that Modeling is a central part of all the activities that lead up to the deployment of good software.
15 Object-oriented software development, developed only in the later part of the Twentieth Century, presented a major advancement in software engineering because it allowed computer logic to be modeled in terms of real-life things. In object-oriented computer programming, all data and functionality is encapsulated in a class, which defines the object's contained information and possible actions. A computer software program thus consists of object instances of these classes interacting with each other.
As contemporary software architects are only too well aware, a useful software design must contain classes that are neither too broad nor too specific, and those classes must be reasonably coterminous with the real-world problems they are meant to solve. In a direct parallel to the civil law and common law modeling techniques in the legal world, the software community is currently divided into two design ideology camps. One school of thought, exemplified by so-called waterfall
development process, mirrors the civil law in its prescription for committee-based comprehensive documents describing a system in detail. The other, exemplified by so-called agile
programming methods method, like the common law calls instead for small, localized models that can immediately fill a need and later be improved as necessary through a series of highly iterative changes.
Software architects, like judges, as a matter of course run into situations in which what at first appeared to be an elegant categorization no longer meets the needs of a new fact pattern or use case.
Agile development processes as well as hybrid methods of software development such as the Unified Software Development Process (USDP) recognize and accept the process of revising models, called refactoring. Recently the software industry has begun to note certain similarities and patterns in what constitutes good models and how refactoring can bring about model improvements. Unlike the profession of law, the profession of software engineering has seen the development of documented, systematic methods for refactoring to bring about consistent results.
At a fundamental level, the evolution of the common law and the iterative improvement of computer software are based upon some of the same analytic philosophy concepts developed in the Twentieth Century relating to conceptions of reality, linguistics, and set theory. At their heart, both professions depend on model creation, model application, and model revising or refactoring as Levi explained decades ago using different words. While the three year training course that is law school tries to help law students develop an intuitive understanding of how law works
and evolves, the software profession is currently ahead of the legal profession in creating procedures and frameworks for identifying what makes conceptual models logically elegant; and when and how these models should be changed. The following pages explain some of these recent developments in refactoring and describe how the lessons learned in the software engineering discipline can provide insight and guidance to analogous modeling dilemmas faced by legislators and judges guiding the evolution of the common law.
Modeling the World
What is a model? It is a simplified view of a part of the world used as a tool for problem-solving—in short, [a] model is a simplification of reality.
16 Simplification brings a model utility; because it is an interpretation of reality that abstracts the aspects relevant to solving the problem at hand and ignores extraneous detail,
17 it focuses on the important aspects of a problem relevant for resolution of a particular set of issues. A model attempts to simplify, not the entire world, but a part of it: the problem domain.18
While a domain model is a simplification of the world, it should be distinguished from the reality being modeled.19 Much like Magritte's famous Betrayal of Images,
20 a model is only a map of reality constructed for a certain purpose. Alfred Korybski, the father of general semantics, eloquently stated: The map is not the territory.
21 Consider the 1973 map of KDB Enterprises in U.S. v. Edward Hamilton (1978),22 which showed the boundaries, roads, terrain, features, and improved areas of Ada County, Idaho.
23 Defendant Edward Hamilton was being sued for copyright infringement because he reproduced this map. His defense was that the original map could not be copyrighted in the first place because it was only a synthesis of public domain information about the land; its copyright was therefore invalid and could not be infringed.24
The court disagreed, making a distinction between the physical features of the land and the depiction of those features in a map:
We rule that elements of compilation which amount to more than a matter of trivial selection may, either alone or when taken into consideration with direct observation, support a finding that a map is sufficiently original to merit copyright protection. … [T]he courts have carefully delineated selection of subject, posture, background, lighting, and perhaps even perspective alone as protectible elements of a photographer's work. … Similar attention to rewarding the cartographer's art requires us to recognize that the elements of authorship embodied in a map consist not only of the depiction of a previously undiscovered landmark or the correction or improvement of scale or placement, but also in selection, design, and synthesis.25
Hamilton was found to have infringed a copyright because the court recognized maps as the quintessential model. Maps can be copyrighted because, however accurate they purport to be, they are distinct from the physical world they represent.26 Maps and models in general vary in their accuracy, can be improved, and must periodically be updated better to facilitate human navigation of a terrain that is better understood over time.
Greek Models
One of the central tasks of modeling is classification, or creating conceptual categories and placing domain objects within these categories. Over 2300 ago, Aristotle laid down many of the fundamentals of this process in his Categoriae.27 He divided the objects of the world into substance, quantity, relation, place, time, position, state, action, and affection.28 The substance
category provides an excellent illustration of the formation of an early domain model.
Of substances
Aristotle declared the existence of primary substances,
such as individual men or individual horses. The secondary substances
were larger categories in which the primary substances were placed. They included for example a genus animal,
a species man,
and a species horse.
Beyond mere categorization, however, Aristotle also pointed out some fundamental features of a modeling framework:
- The
secondary substances
are categories which are distinct from individuals, because each can contain many individuals.29 - Substances have
qualities
(or properties or attributes) such ascolor
, and the property of an individual can change its property (e.g. from black to white) without changing its identity.30 These properties are distinct from categories.31 - Substances can be composed of other substances (i.e. composition) in a relationship of
parts in a whole.
32 - Properties are not be confused with composition. That the category
man
has the quality terrestrial, for instance, is not to say thatterrestrial
isin man
oris part of man.
33 - Contained categories are transitive. That is, if an individual,
Aristotle
, is one of the categoryman
, and the category man is within the categoryanimal
, thenAristotle
is within the categoryanimal
.34
Aristotle in other works goes on to construct entire taxonomies of genus, species, and individuals, along with descriptions of properties and relationships among these categories—an ontology of the world, as it is referred in modern computer artificial intelligence and knowledge representation theory.35 Here Aristotle is concerned primarily, not with a particular ontology, but with a theory of constructing and describing ontologies—a meta-ontology,
as it were. That is, Aristotle is not only explaining the particular categories in which animals fall, he is also making a larger statement about how categories in general relate. Within this meta-ontology, Aristotle's example ontology could be diagrammed thus:36
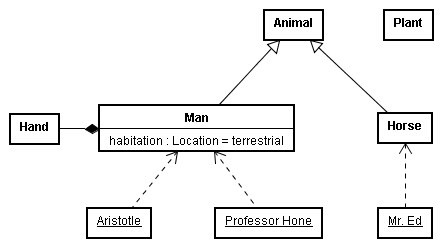
Here Aristotle's categories (or classes) Man and Horse are shown to be subcategories (or subclasses) of the larger category Animal via a directed line with an open triangle pointer. Two individuals, Aristotle and Professor Hone are shown to be instances of the class Man by their underlined names. The class Man is shown to have an attribute of habitation which has the value terrestrial
(e.g. Man has the quality of being terrestrial). The class Man is composed of one or more Hands, each of which is not a quality, but a composed class.
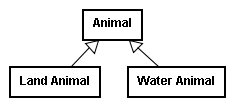
Aristotle elsewhere indicated that one may face several choices in creating a system of categories, and that some of those ontologies may be more useful in describing the world than others. He noted that a naïve approach at categorization might yield a division of animals based upon their habitation, with the Animal category divided into Land Animal and Water Animal. Such a division, although workable, would not yield the best ontology for studying animals, as it would break up a natural group.
Birds, for instance, which Aristotle recognized as a named, natural group, would be split apart using this ontological division.37
Aristotle's system of characterizing domain models extends well beyond the ancient view of the world and can effectively describe domain ontologies in various fields, from the law to computer science. A single ontology may allow a particular problem set to be attacked with ease, but as conditions change and the problem set is enlarged, one ontology may become less useful and need revision. Armed with a meta-ontology of categories, subcategories, properties, and composition; accompanied by a technique for visually representing the model; one can construct an ontology that is most useful for a particular task, or re-architect an ontology to better describe a domain in the face of changing needs.
Transforming Taxonomies
Aristotle's simple taxonomy,38 as touched upon here and described in depth in De Partibus Animalium,39 quickly became inadequate for the needs of modern science. In 1735, Carolus Linnaeus changed Aristotle's two-genus animal and plant division to a three-part division of mineral, vegetable, and animal categorized into a four-level hierarchy of classes of narrowing specificity. Today a multilevel categorization system is used which, although it uses the binomial nomenclature developed by Linnaeus, divides individuals into much more specialized series of categories.40
The Systema Naturae constructed by Linnaeus has proved useful for almost 300 years, but it was created when biological evolution was hardly understood. Today, the system is being increasingly seen as artificial and in need of revision in light of a modern understanding of the relationships among organisms.41 A classification scheme is a model imposed upon reality so that one can better solve problems within that domain. Within the domain of biology, a new ontology could provide a better common language to assist the progress of scientific research. A domain model balances the reflecting reality with the need to address problems within its domain; and a model must be revised if it no longer adequately meets that need.
Legal Models
The law necessarily is built upon a base of classification. In order to apply the law, one must be able to classify the particular items within the domain of its application. Applying the law
is in large part merely a synonym for legal classification within a particular ontology. Within civil law systems, ontology-creation is mostly restricted to statute-writing. Within the common law, however, applying the law and modeling the law go hand in hand, and the history of the common law has proven to be no less than an iterative process of ontology creation and refinement.
The great justice Oliver Wendell Holmes, Jr. saw the law in such evolutionary terms. During an era in which Darwin's On the Origins of the Species42 was bringing widespread awareness of how biological categories are not fixed and evolve through time, Holmes came to regard the study of history—or more particularly the study of history from an
43 In his early writings he compared the study of law to that of science, claiming that the elements of law should be classified into a taxonomy like that in biology.44 He therefore pursued a program of evolutionary
perspective that emphasized the progressive changes in legal doctrine over time—as yielding the key to a scientific
or philosophical
investigation of legal subjects.classifications of legal subjects based on the methodology of natural science, with
45general principles
serving as the equivalent of genus
and the applications of those principles to specific legal issues serving as the equivalent of classes
and species.
One of his first attempts at such a program, presented in Codes, and the Arrangement of the Law,46 attempted to produce a
47 Later in his landmark The Common Law, Holmes started a formal account of the underlying ontology of the law, a model that had implicitly evolved through the evolution of the common law but had never been made explicit.48philosophical
classification scheme for law in light of the breakdown of the writ system of procedure that had served as the basis for doctrinal organization until the early nineteenth century.
Holmes acknowledged that [t]he law did not begin with a general theory [or model]. It has never worked one out.
49 During Holmes' time this assessment was particularly valid, as the order of the law was still clinging to the procedural characterizations of law that obscured its ontology:
Discussions of legislative principle have been darkened by arguments on the limits between trespass and case, or on the scope of a general issue. In place of a theory of tort, we have a theory of trespass. And even within that narrower limit, precedents of the time of the assize and jurata have been applied without a thought of their connection with a long forgotten procedure.Since the ancient forms of action have disappeared, a broader treatment of the subject ought to be possible.50
Procedure-Oriented Law
In the early stages of common law evolution, from the early Middle Ages to the later part of the Nineteenth Century,51 legal characterization was primarily procedural,52 centered on a multitude of forms of action. When one wished to bring an action against a defendant, one would use a writ to choose the form of action most appropriate, be it an action of covenant, debt, detinue, replevin, trespass, assumpsit, ejectment, case, etc.53 This choice [was] not,
as Maitland has pointed out, merely a choice between a number of queer technical terms, it [was] a choice between methods of procedure adapted to cases of different kinds.
54
Once chosen, the form of action would specify the categories of the issues to be considered. In some forms of action, the plaintiff might be classified as a demandant.
In some, the defendant might be termed tenant.
55 More crucially, forms of action conflated distinction between factual scenarios. The procedural writ of detinue, for instance, applied to claims of bailor against bailee as well as to claims of owner against possessor, even though contemporary law finds these situations intrinsically distinct.56
This division based upon procedure rather than ontology allowed the categories within each form of action to evolve independently of the categories of other forms. Each procedural pigeon-hole contain[ed] its own rules of substantive law …. It is quite possible that a litigant [would] find that his case will fit some two or three of these pigeon-holes,
and would thus choose the procedural division that would provide the biggest advantage over the defendant.57 But choosing an arbitrary form of action meant forcing the facts into an even more arbitrary ontology, and thus were born fictions—and Eighteenth Century procedure was full … of fictions contrived to get modern results out of medieval premises: writs were supposed to be issued which in fact never were issued, proceedings were supposed to be taken which in fact never were taken.
58
The owner or bailor within an action of detinue eventually resorted to simply claiming that the thing in question has been lost, and that the defendant had found it—a recitation of a fictional paradigm case formed to follow procedure rather than reflect the underlying facts.59 Still,
says Maitland, these fictions had to be maintained, otherwise the whole system would have fallen to pieces ….
60 Eventually the fictions were too much to bear, however, and beginning in 1833 with the Real Property Limitation Act, which consolidated 60 forms of action, the common law began to move away from a procedure-oriented classification of legal claims.61
Class-Oriented Law
The abolition of forms of action did not mean that the common law was suddenly devoid of procedure—indeed, the Judicature Act of 1873, which finally abolished forms of action altogether, set in place what could be called a code of civil procedure. But under the new system the legal classification is not guided by the choosing of an original writ, but rather vice-versa: the classification of the original facts instead drives the selection of procedure. Rather than forms of action, the common law seeks to create a rational, modern classification of causes of action ….
62 Rather than procedure-oriented, the common law has become what could be called class-oriented.
The move to a class-oriented or ontology-oriented approach to law did not slow the evolution of the law, because ontologies as conceptual models are always imperfect, allowing continuous improvement towards frameworks better able to effect appropriate outcomes. Indeed, as has been noted, many original ontologies were carried over from the old procedural system of writs, and represented long-dead procedures rather than characterizations of real-world objects. The distinction between real
and personal
property, still present in the common law today, in fact in [its] origin denoted not the difference between the objects of property rights but that between the forms of action by which rights were vindicated.
63
The new ontologies did not necessarily change legal outcomes—indeed, it is significant that this paradigm shift in legal modeling was able to change the way the problem domain was characterized while providing the same outcomes as before. As Holmes noted:
[W]e must remember that the abolition of the common-law forms of pleading has not changed the rules of substantive law. Hence, although pleaders now generally allege intent or negligence, anything which would formerly have been sufficient to charge a defendant in trespass is still sufficient, notwithstanding the fact that the ancient form of action and declaration has disappeared.64
Nevertheless, the move from procedure-based law to ontology-based law represents a milestone in the evolution of legal modeling. A law based upon facts is easier to understand, requiring no ontological fictions for application. As its ontologies improve, the law can better represent its domain—the factual cases to which it is applied—and can be better applied to novel situations.
Discovering Legal Ontologies
The importance of appropriate legal ontologies applied to factual circumstances goes beyond mere ability to distinguish among gray lines
separating categories. Ontology building and evolution in the law is an important reflection of how well the law represents current social understandings of reality, and to what extent legal decisions will be relevant to those conceptions. An illustrative case is Schley v. Couch (1955),65 in which the respondent, Couch, found a jar containing old bills worth $1,000 in the earth while digging the foundation of a garage on the property in Texas owned by the petitioner, Schley. Neither party claimed to be the true owner
of the money, but each claimed the right to possess the money until and if the original owner was found.
The trial court submitted to the jury two categories of discovered property:66 Lost property,
or that which the owner has involuntarily parted with through neglect, carelessness or inadvertence,
67 and is to be retained by the finder until the true owner is found; and mislaid property
, that which has been intentionally hidden away by the owner to be later retrieved, but about which the owner later forgets. Mislaid property is to be held by the owner of the premises until the property is reclaimed, while lost property is placed in the possession of the finder. The jury in the trial court classified the property as mislaid
awarded with the money going to the defendant owner of the premises, Schley.68
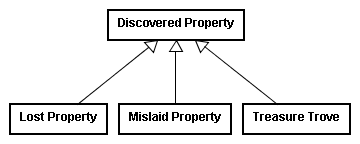
Upon appeal the Court of Civil Appeals reversed the judgment and gave right of possession to the finder. The Court of Civil Appeals recognized the same facts and the same definitions, but recognized a separate ontology in which there existed a third category, treasure trove,
which included money found hidden in the earth with an unknown owner. The appeals court's ontology therefore appeared as characterized by this diagram.
The Supreme Court of Texas disputed this ontology. While acknowledging that there had once been a Treasure Trove category, Justice Griffin writing for the majority argued that this was an ancient
category that applied to treasure hidden by Roman conquerors as they were being driven from the British Isles, expecting to later return and reclaim the buried treasure. Justice Griffin persuasively argued that such an ontological class had no relevance at the present time and under present condition in [the United States].
Responding to a changing view of reality, the Court saw the ontology of discovered property as having been altered, with the Treasure Trove class merged with that of lost goods generally.
69 Of the two remaining categories, the money was classified as mislaid
rather than lost
, as the money apparently had only been hidden at most four years before. The money was thus given to the owner of the premises.
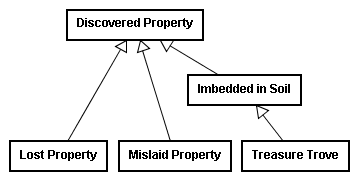
Imbedded in soilclass diagram.
Concurring with the majority's holding, Justice Calvert nevertheless disagreed with the majority's ontology. Although he agreed that the Treasure Trove category had little use in the modern era in a country far away from Roman invaders, he disputed that the category had simply been merged into those of Lost Property and Mislaid Property. It makes no sense that property should, with the passage of time, change from mislaid
to lost
—from one class of discovered property to another. The majority had misinterpreted the ontology, he claimed, and Treasure Trove was simply a specific category of a more general class, personal property found imbedded in the soil.
Removing the Treasure Trove category required no merger, as the general category of Imbedded in Soil still remained; that category gave possession to the owner of the soil and would result in the same holding as that of the majority.70
Justice Wilson also concurred with the majority's holding, agreeing that a contemporary ontology of discovered property should not contain a Treasure Trove class. But he would have gone much further in his ontological modification. In so far as money buried or secreted on privately owned realty is concerned,
he said, the old distinctions between treasure-trove, lost property, and mislaid property seem to be of little value and not worth preserving.
As the true owner is unknown and unavailable, classifying property based upon the true owner's intent is futile. There exists no reason for transferring possession to the finder, or for trying to divine the intentions of a missing owner. Rather, A simple solution for all of these problems is to maintain the continuity of possession of the landowner until the true owner establishes his title.
71 The entire ontology of discovered property should be collapsed into a single category.
Schley v. Couch represents, not a panel of justices arguing over the holding of a case, but a group of ontologists arguing over the best ontology to use in the face of changing circumstances. Their dispute was not over the resolution of the present case, but over a classification system that would be useful outside the present set of facts. They realized that the ontology they established would affect the outcomes of facts in future cases, and that an elegant ontology that best encapsulated society's view of property would be understandable and provide relevant holdings for years to come.
Roman Models
In many ways the common law is a late-comer to the concept of ontological modeling. The very Romans whose left-behind treasures had given rise to the concept of treasure trove were responsible for creating an entire system of law with an internally consistent ontology. This system, as it evolved into the civil law tradition known today, discovered its own ontology hundreds of years before the common law.
Around the time of Aristotle, Roman law, like the early common law, relied on a limited number of forms of action.72 Unlike the statute-centered civil law of today, classical Roman law focused on real and hypothetical cases. As Peter Stein relates, Inevitably a casuistic system becomes intricate and complex and in need of categorisation and systematization. The process of putting the [Roman] law in some form of order began in the late republic under the influence of Greek methods of classification.
73
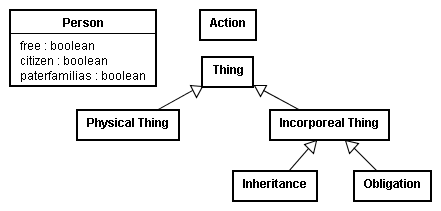
In the middle of the second century a law teacher named Gaius made a major advance in the classification of the law, creating a legal ontology in which everything is a Person, Thing, or Action. Under the ontology of Gaius, a person has several properties: freedom (free or slave), citizenship (citizen or peregrine), and family position (paterfamilias or head of family; or under the power of the ancestor
).74 (The diagram here shows the attributes of the class Person using the term boolean,
75 indicating that each attribute can be either true
or false.
) Besides showing actions as ontological entities on par with persons and things, Gaius' ontology was novel in that it recognized both physical and incorporeal things as falling within the same more general category, and in that it recognized inheritance and obligation as incorporeal things.76
During the Middle Ages glossators in Bologna creating glosses on the Roman law as compiled by the Byzantine Emperor Justinian in the Sixth Century.77 The glossators compiled distinctions, elaborate classifications with many divisions and sub-divisions, sometimes illustrated by diagrammatic tables.
78 In the Thirteenth Century several European countries began setting down local laws borrowing the categories in the Roman law.79
In the Sixteenth Century, with the Renaissance return to classical philosophy, humanist professors at Bourges, France believed that law should be organized into scientifically
subdivided categories,80 as Holmes would later hope to do with the common law. François Duaren in particular argued that law should be expounded in the same way as other sciences,
systematically classifying the components of the law from general to particular.81 A century later mathematician and jurist G. W. Leibniz published Nova methodus discendae docendaeque jurisprudentiae, in which he sought to create a more logical correspondence between the civil law and nature by re-arranging the Roman law according to idea of natural law.82
A Hybrid Approach to Modeling
In the civil law systems that have evolved from the Roman law, enacted law rather than previous court cases has traditionally been the pre-eminent source of law.83 Civil law systems have followed the tradition of logically categorized, internally consistent frameworks of categories. The common law, with its reliance on precedence for forming new legal concepts, instead focuses on categories appropriate for deciding individual cases, with later cases modifying and/or extending these categories as necessary. The civil law approach to ontology-building can thus be classified as top-down, concentrating on a complete framework in advance of legal application; while that of the common law can be classified as bottom-up, concentrating on localized models that evolve iteratively as new information is presented.
The traditional divide between the two systems is narrowing, however, as legal systems discover the benefits of deriving categories from real-world experience yet without losing sight of a larger ontological view. As the increasing flood of precedents
began to make the common law cumbrous and unmanageable,
the American Law Institute (ALI) was tasked with creating restatements of the law.84 While not as authoritative as precedent, these restatements nevertheless attempt to capture the substantive law of previous decisions while arranging them into clearly ordered systems. If rules among states are inconsistent, the ALI regularly chooses that which it feels most progressive, even if that doesn't represent the majority of precedents across states.85 It has been noted that restatements are rather like the Civil Law codes in their systematic structure of abstractly formulated rules,
86 applying a top-down civil law mindset in which ontology gains primary importance.
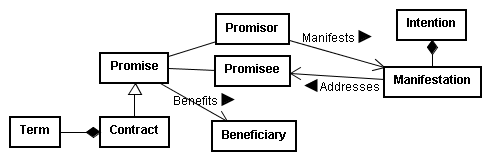
The Restatement (Second) of Contracts, for instance, starts out very much like civil law legislation, clearly describing the ontology it uses to model the domain of contracts with classes such as Promise, Agreement, Contract, Bargain, Intention, Manifestation, Promisor, Promisee, and Terms.87 The diagram presented here provides a loose diagrammatic representation of the ontology presented in the first few sections of that Restatement.88
Precise, consistent, yet usable ontologies are many times intricate, and may require modifications over many iterations, something the ALI through restatements has taken great pains to do. Similarly in England the Law Commission has been given the task to take and keep under review all the law … with a view to its systematic development and reform, including in particular the codification of such law
and contemporary discussion has advocated codification in light of civil law codes.89 On the other side of the coin, judges in civil law countries are playing a large and constantly growing part in the development of law.
90 As one legal writer has explained, the common law and civil law traditions are moving towards a hybrid ontology-building approach that takes into account individual cases and well as the need for an overarching consistency:
[O]n the Continent the days of absolute pre-eminence of statutory law are past; contrariwise, in the Common Law there is an increasing tendency to use legislation in order to unify, rationalize, and simplify the law. On the Continent, law is increasingly being developed by the judges and consequently there is more room for an inductive method and style related to the actual problems; contrariwise, the Common Law is seeing the need to bring the rules developed by the judges into a systematic order by means of scholarly analysis and legislative action, so as to make them easier to understand and master. There are therefore grounds for believing that although the Common Law and the Civil Law started off from opposite positions, they are gradually moving closer together even in their legal methods and techniques.91
Computer Models
Machines that perform specified tasks have been around since the early 1800s,92 but the invention of the transistor along with the creation of electronic computers in the following century made general-purpose problem-solving feasible. The first electronic computers did not allow arbitrary instructions—they were hard-wired
93 in a literal sense, with switches … set by the programmer to connect the internal wiring of a computer to perform the requested tasks.
94 In the late 1940s John von Neumann released the potential of general-purpose computers through his idea of storing a series of electronic codes95 rather than physical wires to direct a computer's actions.96
Procedural Programming
Because computers do not natively understand natural
or human languages, these electronic codes represent commands understood by the computer. A collection of formally defined command codes represents a computer language: [A] notational system for describing computation in machine-readable and human-readable form.
97 The first computer languages were simply sequences of instructions or imperatives; these early languages are thus classified as procedural.98
The procedural programming paradigm remained popular for several decades and has been, as one historian writes, the mainstay since the Bronze Age of computers ....
99 Significant developments in the early 1960s, for example, did not change the procedural aspect of computer programming, but instead merely helped to abstract programming code into functions
and procedures,
100 which summarized a program segment in terms of a name and a parameter list.
101 In other words, directly analogous to the forms of action in the early common law, programmers learned to give a name to a particular set of instructions, and to indicate the parameters
or the types of data that would be acted upon by the instructions. For example, under the writ system a set of instructions to the sheriff to return illegally seized property was named Assisa Novae Disseisinae
and spoke in terms of complainer
, tenements
and chattels.
102 An analogous programming procedure might be giveEverythingBack( complainer, tenements, chattels ), indicating the procedure name and required parameters.
By the 1970s, computer scientists were struggling to address more complex issues and new applications of computer technology. D. L. Parnas of Carnegie-Mellon University in 1972 attempted to better structure procedural programs, providing guidelines for decomposing computer programs into modules of related functionality.103 In 1984 Mary Shaw, also at Carnegie-Mellon, indicated that programs could be made more complex and yet more reliable if they were viewed as abstractions of reality. Specifically referring to the way in which maps simplify reality, she wrote:
An abstraction is a simplified description, or specification, of a system that emphasizes some of the system's details or properties while suppressing others. A good abstraction is one that emphasizes details that are significant to the reader or user and suppresses details that are, at least for the moment, immaterial or diversionary.
Abstractionin programming systems corresponds closely toanalytic modelingin many other fields.104
Object-Oriented Programming
Scientists in Oslo, Norway intent on creating computer simulations of real-world conditions were already particularly keen on finding ways to create abstract models of the world. In the 1960s Kristen Nygaard and Ole-Johan Dahl at the Norwegian Computing Center created a programming language specifically for simulations, naming it Simula.105 Rather than grouping program modules based upon procedural instructions, Simula grouped modules based upon actual real-world objects.106 Just as the common law after the Judicature Act of 1873 classified legal actions based upon the entities of the underlying facts rather than a specific form of action, Simula arranged its modules around the concept of a class—an abstraction of a real object in the world. Simula67, the version of the language created in 1967, can be called the first object-oriented107 programming language.108
While object-oriented approaches to computation in the 1960s was being studied in the labs and used in special domains such as simulation, it did not gain widespread acceptance until the 1980s after the development of the C++ language.109 Bjarne Stroustrap AT&T Bell Labs attempted to mimic the classes of Simula in a popular programming language called C.110 In 1982 Stroustrap named his new language C with Classes
because it introduced the encapsulation notion of a class or category, as had Simula.111 The name was later changed to C++.112 In the 1990s James Gosling at Sun Microsystems removed some of the procedural aspects of C++, and created a language that was more object-oriented and simpler than C++. When this new language was released in 1996, Sun called it Java.113 Currently Java is one of the most popular object-oriented programming languages, and one closely associated with Internet-related computer programming. The object-oriented programming examples in this essay are written in Java.
Primarily object-oriented programming languages rest on the notion of classes, which are analogous to the categories of Aristotle. Object-oriented languages make a distinction between a class and an object, the latter being an instance of a particular class. Aristotle was describing this distinction when he described the difference between primary substances
and secondary substances.
114 Using Aristotle's categories as an example, there is only one class Man, although there may be several instances of that class. In object-oriented programming terminology, Aristotle and Professor Hone are both objects, instances of the class Man.
There are several characteristics that make a programming language object-oriented. Through use of the class, object-oriented programming languages exhibit encapsulation: the class ties together or encapsulates
data and any procedures used to manipulate that data.115 In reference to Aristotle's hierarchy mentioned earlier, one can say that the class Man encapsulates the notion of habitation. In other words, the definition of the class Man carries with it the information regarding habitation location.
A second common characteristic of object-oriented programming languages is the concept of inheritance. Rather than redefining anew all encapsulated data and functionality in a class, a class inherits
the data and functionality of its parent class.
Aristotle's class Man analogously inherits the common information and functionality of the class Animal. Inheritance in object-oriented programming allows one to substitute an instance of a child class
or subclass
such as Man anywhere the context requires an instance of the parent class, in this case Animal. Such substitutability was described precisely by Aristotle:
When one thing is predicated of another, all that which is predicable of the predicate will be predicable also of the subject. Thus,
manis predicated of the individual man; butanimalis predicated ofman; it will, therefore, be predicable of the individual man also: for the individual man is bothmanandanimal.116
Object-oriented classes distinguish among inheritance and composition or containment. Aristotle, in stressing that classifications are not in
an object such as a part is related to a whole, was making the same distinction.117 Object-oriented programming languages allow classes to have child classes as well as to contain other classes through composition. Writing a useful set of classes in an object-oriented programming language many times requires a decision on whether a class should subclassed or contained—whether inheritance or composition should be used.118
Using the Java programming language, the ontology presented by Aristotle earlier can be described precisely and succinctly. Here the major classes of Animal, Plant, Hand, Man, and Horse are defined. The habitation of Man is shown to be a property of the type Location.119 Man is shown to contain two instances of the class Hand. Two instances of Man are then created, followed by one instance of Horse.
class Animal{} class Plant{} class Hand{} class Man extends Animal { Location habitation=terrestrial; Hand leftHand=new Hand(); Hand rightHand=new Hand(); } class Horse extends Animal{} Man Aristotle=new Man(); Man professorHone=new Man(); Horse mrEd=new Horse()
The powerful abstraction techniques of encapsulation, inheritance, and composition make object-oriented programming more than just a language paradigm; it is a methodology for program design.
120 Modeling the problem domain in a class-oriented fashion allows the components of an entire system, along with their relationships and interactions, to be described before a line of programming code is ever written. Most recent developments in object-oriented programming have concentrated on the best techniques to model the universe of a problem domain and to create useful ontologies from which software implementations can be written.
Seeing the Model
A significant step in the advancement of ontology modeling was the creation of the Unified Modeling Language (UML).121 While an object ontology may be rigorously specified in various formats, humans in many cases more quickly understand visual representations of information.122 Between 1988 and 1992, following on the heels of the invention of C++, several leading object-oriented programming experts, among them Grady Booch, Ivar Jacobson, and Jim Rumbaugh, introduced books describing techniques for graphically modeling relationships in object-oriented languages.123 Although the notations used by the authors were similar, they had several differences which ultimately caused confusion. Working in 1996 under the auspices of the Object Management Group (OMG)124, Booch, Jacobson, and Rumbaugh merged their notations,125 producing the Unified Modeling Language in 1997.126
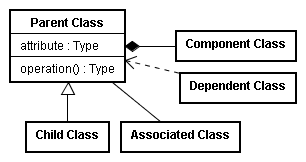
The UML actually specifies several types of diagrams for describing an ontology.127 The most often used UML diagram is the class diagram, which was has already been introduced in this work to graphically illustrate the categories of Aristotle; the classes within the Discovered Property
ontology, and the primary classes of the Restatement (Second) of Contracts. The UML class diagram uses rectangles to indicate classes, underlined names to indicate class instances, and a line with a closed arrowhead to indicate inheritance—generalization and specialization in the terminology of the UML. Each class also indicates its properties (attributes in UML) and procedures (operations in UML), along with their data types.
UML also allows the representation of composition in which a component class is a part of a larger whole.128 Classes that depend on other classes can be represented using a dotted line with an open arrowhead. While created for object-oriented software modeling, the UML class diagram provides a consistent and straightforward graphical representation for communicating any ontology.129
Domain-Driven Modeling and Refactoring
The widespread use of object-oriented languages such as Java, combined with a standardized graphical modeling notation, allowed a new concentration on ontology creation and maintenance through domain-driven design and refactoring. Domain-driven design
is a term introduced in 2004 by Eric Evans in his book, Domain-Driven Design: Tackling Complexity in the Heart of Software130 to describe a philosophy [that] has emerged as an undercurrent in the object community ….
131 The techniques Evans lays out shows how large systems that are understandable, verifiable, maintainable, and extensible are best approached by creating and continually improving a common view of the problem domain—the domain model.
Crucial to domain-driven modeling is recognition that any model by definition is an incomplete specification, along with an understanding of how models can be analyzed and modified to better reflect the domain. In the computer science field, formal studies in this area began under the rubric refactoring
as presented in a 1992 Computer Science PhD thesis by William Opdyke entitled Refactoring Object-Oriented Frameworks.132 Opdyke's thesis defines a set of object-oriented restructuring operations (refactorings) that support the design, evolution, and reuse of object-oriented application frameworks.
133
Opdyke describes several ways to restructure object models, and he emphasizes that these methods are in most cases behavior-preserving.
That is, while refactoring may change the conceptualization of reality in order to better understand and use the system under new scenarios, the system before and after the refactoring should produce the same results134—exactly the point Holmes was making when he noted that the common law produced the same results after moving from the writ system, but had the advantage of being more consistent and understandable.135
Opdyke's seminal description of refactoring divides common refactoring tasks into two groups: low-level and high-level. The low-level refactoring tasks have to do with the structure of computer code, but the high-level refactoring tasks address the overall architecture of software frameworks—fashioning an appropriate ontology for modeling a problem domain. Opdyke describes three main types of high-level refactorings in detail: generalizing the inheritance hierarchy, specializing the inheritance hierarchy, and using aggregations (i.e. composition) to model the relationships among classes.136
These high-level refactoring tasks involve seeing ontological classes that, based upon the current understanding of the problem domain, no longer adequately encapsulate what are viewed to be the things
that are deemed to exist. Generalizing the inheritance hierarchy, for example, involves the recognition that distinct classes that have been described in an ontology may not after all represent distinct things
in the domain, and should be groups as child classes under a more general parent class, or conflated into a single class. In words that bring to mind Peter Stein's comment that [i]nevitably a casuistic [legal] system becomes intricate and complex and in need of categorisation and systematization,
137 Opdyke explains that computer systems are often designed to satisfy current use cases, and must be modified after being presented with new examples in the problem domain:
As the design of an application framework matures, general concepts are usually derived from specific examples. Often, these examples are implemented in concrete classes that intertwine the case-specific behavior with more general, common abstractions. As common abstractions are determined, it is useful to separate these abstractions from the example-specific behavior. One way to do this is to define an abstract superclass for a set of concrete classes, and migrate the common behavior to that of the superclass. The refactoring not only clarifies the design of the framework, but better ensures consistency by defining the abstractions in one place. The concrete classes retain the behavior, although it is now inherited rather than being locally defined.138
Describing the use of aggregations to model the relationship among classes, Opdyke touches on the distinction between child classes and composite relationships noted by Aristotle:139
Whole-part relationships among objects are sometimes not obvious until implementation is underway. A relationship might first be modeled using inheritance and later is refined into an aggregation. Refactorings can help make aggregations more explicit, and make component classes more usable.140
Since Opdyke published this first treatise on refactoring, others have begun to collect lists of common refactorings that are useful guides in redefining software domain models. Martin Fowler's Refactoring: Improving the Design of Existing Code141 in 1999 and Joshua Kerievsky's Refactoring to Patterns142 in 2005 are two famous examples. As understanding of object-oriented modeling has improved, the latest discussion on refactoring in the computer science community, including Eric Evan's Domain-Driven Design in 2004, has increasingly centered on a domain model-centric modifications of software designs. As early as 1997 Bertrand Meyer in his classic Object-Oriented Software Construction, Second Edition realized the importance of proper domain modeling when he addressed danger signals
that indicate less-than-optimal choices in determining which classes should exist in an ontology. Meyer describes a performance-oriented class an example of one that might not actually represent a valid category in the domain:
In a design meeting, an architecture review, or simply an informal discussion with a developer, you ask about the role of a certain class. The answer:
This class prints the resultsorthis class parses the input, or some other variant ofThis class does….The answer usually points to a design flaw. A class is not supposed to do one thing but to offer a number of services (features) on objects of a certain type. If it really does just one thing, it is probably a case of the Grand Mistake: devising a class for what should just be a routine of some other class.143
Software Development Processes
Software domain models and their refactorings nowadays live within a larger software development process. As software systems have become larger, more complex, and more interrelated, documented techniques for managing information and guiding the development process have emerged. Because software projects, like the law, must continually address new situations, all software development processes to some extent accept evolution as an inevitable part of software design and maintenance, but current software development methodologies differ in their emphasis of when within the process refactoring should occur.
The conventional
software process is the waterfall model, in which requirements gathering and design is done up-front, and actual program implementation is done in later stages. The waterfall process is a linear workflow in which work products, such as requirements documents, are handed off between a series of stages including requirements capture, analysis, design, and implementation—much like the unidirectional flow of objects along multiple tiers of a waterfall.144 One drawback with such a top-down methodology arises when changing requirements in the domain (which could very well occur in the space of time during which a requirements document is fully and rigorously hammered out in the earlier stages) requires swimming upstream
to a revisiting of earlier decisions:
… The basic framework described in the waterfall model is risky and invites failure. The testing phase that occurs at the end of the development cycle is the first event for which timing, storage, input/output transfers, etc., are experienced as distinguished from analyzed. The resulting design changes are likely to be so disruptive that the software requirements upon which the design is based are likely violated. Either the requirements must be modified or a substantial design change is warranted.145
Reacting to such processes that require a large investment in design up-front and a large penalty for changes later in the process, around the year 2000 some began to advocate agile
processes that provide for little up-front design combined with frequent refactorings throughout the development cycle. One of the standard-bearers of these new breed of processes is Extreme Programming, or simply XP. Kent Beck in Extreme Programming Explained: Embrace Change claims that XP is meant to flatten the curve
of the exponential rise of software modifications that are pushed off to later stages of development.146 To accomplish this, XP relies on little up-front planning coupled with simple design, small releases, and repeated refactoring.147 Like a common law judge hesitating to design a large, intricate doctrine that might be demolished when presented with yet-to-be-discovered cases, XP requests that software developers ask, What is the simplest thing that could possibly work?
148
Such an extremely bottom-up procedure such as XP, in which architecture
hopefully emerges as the system evolves, has had its share of critics. Michael Stephens and Doug Rosenberg in 2003 published Extreme Programming Refactored: The Case Against XP.149 Stephens and Rosenberg recognize, in language that that brings to mind complaints against civil law bureaucracy, that XP is typically seen as the antithesis to
150 They assert, however, that no detailed written requirements up-front can be just as bad as too many of them, leaving the project high-ceremony
methodologies (i.e., prescriptive software processes that demand large amounts of paperwork and many hoops to jump through before any code gets written).without a particularly solid idea of where it's going to end up.
151 They point out that instead of discovering emergent design,
many XP programmers wind up fighting emergent entropy
as many small less-than-desirable decisions get built into the system.
If the waterfall model is to stiff civil law statute-writing as extreme programming is to the nimble and evolutionary common law, the Unified Software Development Process (USDP) resembles the hybrid techniques discussed earlier in which the worth of up-front planning is recognized in tandem with the value in learning from past decisions and changing ontological characterizations to meet contemporary needs. The USDP sees architecture as the central priority,152 yet allows for iterative, incremental refactoring to ensure that the architecture remains relevant to the domain being modeled.153 The USDP and methodologies like it are increasingly seeing the benefit of using a modeling language such as UML to describe and maintain an ontology, while still using iterative domain refactoring as needed.154
Lawmaking and Software Design
The study of law and the development of computer technology have therefore taken similar paths, exhibiting strong similarities in philosophical foundation, evolution, and practice:
| Jurisprudence | Computer Science | |
|---|---|---|
| Procedural Stage | forms of action under writ system | functions and procedures in procedural programming |
| Class-oriented Stage | causes of action emphasizing factual characterization over procedure | object-oriented programming languages emphasizing class representations over procedure |
| Systematic Reformulation Stage | formal restatements; hybrid convergence of top-down civil law and bottom-up common law | formal refactoring; hybrid convergence of top-down waterfall modeling processes and bottom-up agile modeling processes |
Separated at Birth?
The similarity of the legal and computer worlds is not merely coincidental, for both the law and computer science rest on common philosophical underpinnings. The quest, shared by both disciplines, of modeling the world as the interaction of categories of objects, is no less than the quest of metaphysics, the discipline founded by Aristotle.155
So metaphysics considers things as beings or as existents and attempts to specify the properties or features they exhibit just insofar as they are beings or existents. Accordingly, it seeks to understand not merely the concept of being, but also very general concepts like unity or identity, difference, similarity, and dissimilarity that apply to everything that there is. And central to metaphysics understood as a universal science is the delineation of what Aristotle calls categories. These are the highest or most general kinds under which things fall. What the metaphysician is supposed to do is to identify those highest kinds, to specify the features peculiar to each category, and to identify the relations that tie the different categories together; and by doing this, the metaphysician supposedly provides us with a map of the structure of all that there is.156
The central question of metaphysics (and moreover one of the central questions both of law and of computer science) is more than to which category an object belongs—it is the question of which categories exist. The members of the ALI formulating restatements must determine which categories most accurately describe the legal domain being addressed. Those designing computer software architectures must decide which classes most accurately represent the domain represented by use case requirements. Both of them are performing the same act performed by a metaphysical philosopher deciding which categories should enter an
157official
philosophical inventory of things that are. Such an official
inventory is … an ontology.
One of the chief aims of Justice Holmes was to provide a complete catalog of the law along the lines of the natural sciences. As Michael Loux explains, such a project is a metaphysical one following in the steps of Aristotle: to provide a complete catalogue of the categories under which things fall and to identify the sorts of relations that obtain among those categories. … Aristotle believed that an account of this sort is the goal of the metaphysical enterprise.
158
Law and informatics are thus twins born of the same metaphysical quest, their development extending through two independent lines that through the ages have crossed more often than might be expected. Consider the relationships among the works and ideas of the great thinkers of each field:
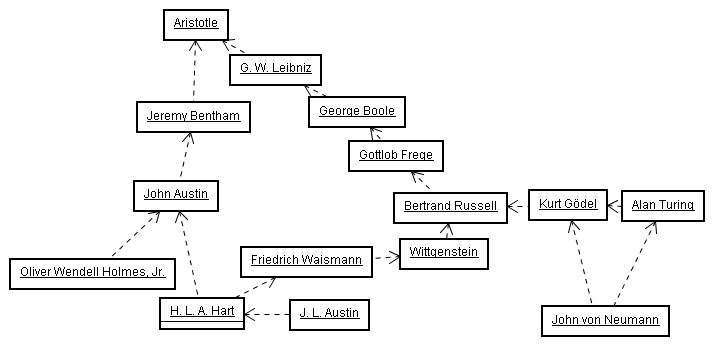
The core philosophy of John Austin, one of the founders of legal positivism, owes an intellectual debt
to the utilitarian philosopher Jeremy Bentham,159 who was concerned classifying a subject into subclasses according to principles set down by Aristotle.160 Holmes' philosophy was a reaction to the command theory of law set forth in John Austin's The Province of Jurisprudence Determined,161 although his conviction that law could be separated from morals followed directly in Austin's footsteps. Austin can therefore be seen as a precursor to Holmes' metaphysical project:
Austin hoped that purifying the concepts of law of their moral content would reveal the law's essential principles. He discerned that the crucial analytical problem was to develop a methodology that could see behind the
technical languageof a given legal system. His solution to this lay in establishing a universal system of logical classification based on uniform and rigorous definitions ….162
G. W. Leibniz, mentioned earlier, had a similar goal of legal recategorization centuries earlier when he went about restructuring the Roman civil law for Baron Johann von Boineburg of Germany, as described earlier.163 Leibniz' bachelor's thesis examined Aristotle's metaphysics, and for his master's thesis he went on to examine the relationship between philosophy and law. For his second bachelor's degree, Leibniz wrote yet another thesis in which he discussed applying systematic logic in the law.164
The classical logic of Aristotle had fascinated the young Leibniz,
165 and it was Aristotle's categories that inspired Leibniz to develop what he called his wonderful idea
of an alphabet representing concepts.166 In the Nineteenth Century, George Boole had interests along the same line when he found the subject of logic essentially as Aristotle left it two millennia earlier.
167 He realized that the syllogisms used by Aristotle were actually special kinds of inferences from a pair of propositions: a premise and a conclusion.168
Boole pointed out that logic extends beyond syllogistic reasoning to include secondary propositions, expressing relationships among other propositions.169 Furthering Leibniz' dream of an alphabet of concepts, Boole created an algebra for the interrelationship among true and false propositions.170 The basis of computer science relies on this Boolean logic, in which binary true/false conditions are represented in electrical on/off states.171
In 1879 Gottlob Frege published Begriffsschrift,172 considered by some to be the most important single work ever written in logic. Going beyond Boole's algebraic representation of the relationships between primary and secondary propositions, Frege introduced a symbolic notation for analyzing individual propositions themselves.173 Frege's work went mostly unnoticed until in 1903 the British philosopher Bertrand Russell174 realized its significance. A decade later Bertrand Russell and Alfred North Whitehead published Principia Mathematica,175 in which they attempted to prove the entirety of mathematics through a series of propositions and inferences, using symbolic logic.176
In 1931 a mathematician named Kurt Gödel illustrated that, however hard Russell and Whitehead tried, there would forever be certain propositions that lie outside a closed system of analytical proofs and cannot be proved within that system. His demonstration used symbolic logic to assert propositions about the propositions within a system using the system's own propositions.177 John von Neumann, already mentioned as one of the figures greatly responsible for making electronic computing possible, was attending the symposium at which Kurt Gödel had dropped his bombshell
about the incompleteness of Russell's Principia; apparently von Neumann had been the first to grasp the significance of Gödel's work.
178 John von Neumann applied Gödel's idea of a symbolic system reflexively representing its own proofs with fellow mathematician Alan Turing's concept of a generic symbolic instruction set to produce a revolutionary idea: a sequence of generic data values in a computer memory representing instructions to guide the computer in the manipulation other data values.179 Today's object-oriented computer programming languages are meta-abstractions upon a symbolic instruction set that uses the von Neumann architecture.180
While Gödel's discovery had damned Russell's project yet allowed the rise of modern computer programming, Russell's student, the Austrian philosopher Ludwig Wittgenstein, helped found the modern study of the philosophy of language.181 This discipline concentrates on how spoken language conveys meaning; when Boole, Russell, and Gödel talk about propositions, the philosophy of language analyzes how those propositions reference concepts in the real world
and how one can make assertions about those concepts.182 When Aristotle talks of a man being an animal, the philosophy of language examines what how language can assert the existence of a category and an instance within that category.
Wittgenstein contradicted the common-sense notion of categories reflecting clear-cut groups of objects when he advanced his family resemblance
theory. Wittgenstein proposed that categories do not denote a fixed number of objects by the properties they share, but rather that various members of a category may be related to each other in some ways even though all the members are not related by the same way.183 Wittgenstein's family resemblance concept inspired H. L. A. Hart (through Friedrich Waismann) to discuss the open texture
184 of legal categories expressed in natural languages when in The Concept of Law he sought to improve (as had Holmes) on John Austin's legal classification program.185 That legal categorizations fall squarely within the realm of the philosophy of language is exemplified, not only by Hart's reliance on Wittgenstein and on Aristotle's Categories,186 but also by the reference of philosopher J. L. Austin to Hart in the seminal work on speech act theory, How to Do Things with Words.187
Family Reunion
The philosophy of language and the study of propositions are currently bringing together the symbolic analysis power of computers with the categorization-dependent discipline of the law. Because law and computer have a common goal of creating ontologies to model the world, modern computer artificial intelligence applications have begun to create symbolic representations of ontologies and propositions about instances or particulars
to be classified within those ontologies—in particular, creating ontologies for computer reasoning based upon legal models.
Objectivist computer reasoning recognizes that the ontological notion of a man being part of an animal category is no less than the assertion of a proposition; specifically,
Similarly, that Aristotle is a man is merely a proposition that Man is a subclass of Animal.
Categorization of any set of objects (including the facts of a legal case, for instance) can be performed by a set of propositional assertions regarding those objects within an ontology. Furthermore, definition of the ontology itself can be done with a set of meta-assertions describing the categories within the ontology as well as their relationships.Aristotle is an instance of the class Man.
Once such computer representation format for ontological definitions is the Resource Description Framework (RDF)188 created by the World Wide Web Consortium (W3C)189 for semantic representation of information on the Internet. Using RDF for defining objects in conjunction with the OWL Web Ontology Language190 (itself represented in RDF) for defining ontologies, researchers are attempting to tease out the ontologies that have been essentially refactored by judges and legislators; expressed in statutes; and implicitly placed in common law cases; and to represent them in computer-understandable format. The hope is that propositional logic, if applied to a clearly stated set of ontological commitments and assertions, can clarify, improve, and to some extent automate legal reasoning191—a goal not unlike those of Leibniz, Holmes, and Turing.
As one example of computer-based representation of a legal ontology, the following diagram represents an effort by researchers at the University of Madrid to model the basic concepts in Spanish Law:192
Refactoring the Law
Recognizing the shared philosophical basis of legal doctrines and object-oriented programming; and learning the tools developed in the parallel discipline of computer information science provides a useful meta-model for analyzing the evolution of legal concepts. Seeing the law as a set of iteratively-developed ontologies allows the law to be analyzed as to fitness for application within its problem space. Modeling languages such as the UML, along with other tools used to analyze ontologies in computer science, can allow the picture of the law's models to become clearer and better solutions to be more readily seen. Such analysis can be applied across the law; here the benefit of an ontological mindset is illustrated in the analysis of property law in the English legal systems.
The Ontology of Property Law
The English law of property shows one of the earliest tendencies towards an ontology-oriented characterization, with property-related ontologies evolving long before the abolition of the writ system. This tendency no doubt reflects that the domain of property law is most directly traceable to objects in the real world.193 Property law ontologies have changed through the centuries to represent contemporary social, political, and religious conditions. As societal realities changed, these ontologies would evolve. When the disparity between ontology and reality widened, the ontological foundation of property law was restructured to create new classes and relationships more reflective of reality and more effective in administering the law.
After the Norman Conquest of England in 1066, William the Conqueror redistributed lands formerly held by the Saxon nobility, thus establishing a new Norman aristocracy.194 William used feudal tenure as the basis of property rights. Under this system all land was ultimately owned by the king; under him were tenants-in-chief, who were usually required to provide knights to the king should he decide to make war. Each tenant-in chief in turn was a lord over other tenants of lower social standing. At the end of the chain of tenancy were the tenants paravail—the peasants actually tilling the soil.195
By the time of Edward I in the late Thirteenth Century, medieval property law ontology was firmly in place.196 Using UML, the tenancy ontology looked something like this:197
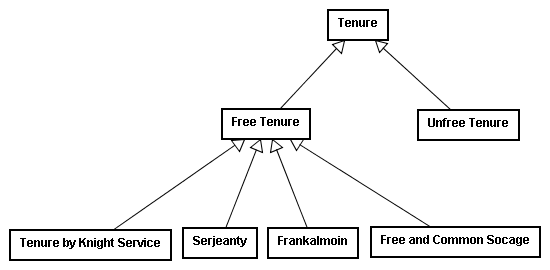
Here the class of Tenure was subdivided into two categories, Free Tenure and Unfree Tenure. Free Tenure was furthermore divided into sub-categories, each describing different characteristics of the tenancy and various obligations of the lords and tenants within that category. As Aristotle noted about such depictions, each sub-category or class took on the general characteristics of its more general class. Anything that could be generally said of a Free Tenure, for example, could also be said about the more specific tenancy of Frankalmoin.
Legal ontologies, like all models, are static simplifications of a changing world. Around the time medieval property law ontology was firmly established, property as a source of knights for a king's war was becoming inadequate and the entire system of feudal system military tenure was becoming obsolete.198 English property law therefore began to work out a new tenancy ontology based primarily not upon a tenant's relationship and obligations to a lord but on an individual's relationship to property measured in time.199
This new ontology, the doctrine of estates,
evolved over hundreds of years. Its great genius
is that it allows ownership of land to be carved up into different successive slices or
200 A estates
and that of these estates
only one of them need be a present possessory estate.Life Estate,
for instance, is a category of ownership indicating that the owner's interest in the property extends only as far in time as the owner is alive; others may hold an interest after this point, although those others do not have possession of the estate while the current owner is alive. From the Fourteenth Century to the present the estate ontology has evolved and the number of classes within the ontology has grown considerably, as can be shown in the following diagram:
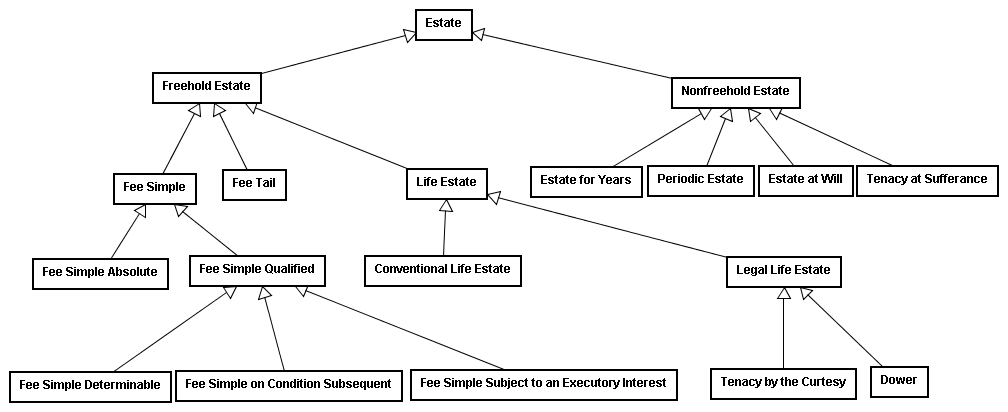
If the transition from a tenure-based ontology to an estate-based ontology illustrates the complete replacement of one ontology with another, the evolution of the estate-based ontology provides an excellent illustration of how a single ontology can be mended and restructured to better represent changing conditions and expectations. The Fee Tail category, for example, was created in 1285 by the statute De Donis Conditionalibus and allowed for one to keep real property within a family. By invoking the phrase to B and the heirs of his body,
A would create an estate that would last only so long as there were lineal descendants of B. At the time that all lineal descendants of B died, perhaps hundreds of years later, the property would revert to the donor or his/her heirs.201
Although the fee tail was created in response to societal desires, eventually such legal restrictions of property ownership to a single family became undesirable. Moreover, as an ontological category Fee Tail proved burdensome and reflected an artificial restriction on alienability of property. The courts begin to allow ways to evade the statute, such as a fictitious law suit called common recovery
and certain actions that could convert the fee tail to a fee simple. As has been noted earlier, the use of fictions to evade an ontological structure is an indication of its unsuitability and a harbinger of its demise—in 1833, England abolished the fee tail and permitted such property to be converted to a fee simple.202
In the United States property law has retained essentially the same ontology since the American Revolution,203 and parts of the property law model are only now beginning to be refactored.204 A case in point involves two of the subclasses of Fee Simple Qualified: Fee Simple Determinable and Fee Simple on Condition Subsequent. Under the traditional ontology, if A conveys property to B so long as no alcohol is sold on the premises,
the estate is said to be a Fee Simple Determinable and A retains a possibility of reverter.
If on the other hand A conveys property to C but on condition that if liquor is sold on the premises A shall have the right of re-entry and C's estate shall become null and void,
the estate is said to be a Fee Simple on Condition Subsequent, leaving A right of entry.
This slight change of wording supposedly creates two different classes of things, the major distinction being that for the former class the estate ends automatically
when liquor is sold on the premises, while for the latter class the estate continues until A exercises the right of entry
or power of termination.
205
In an earlier quote, Bertrand Meyer pointed out that in designing object-oriented computer models, defining a class by what it does
rather than what it is
usually points to a design flaw.
206 Several legal scholars have applied analogous reasoning to the division of Fee Simple Qualified estates and found the division artificial. While other estate classes are arranged according to the length of their life or whether they contain the possibility that ownership can be taken away, the main distinction between Fee Simple Determinable and Fee Simple on Condition Subsequent is procedural: only the latter supposedly requires the original owner to take explicit action to recover the property.
In 1953 Professor Allison Dunham at the University of Chicago Law School pointed out that even this procedural distinction is largely chimerical in modern society. Neither [B] nor [C] wants to give up the land on the happening of the event,
she points out, and both [will] employ lawyers to resist [A]'s demand.
However legal textbooks might classify the result of the original transaction, Dunham shows that in modern times A must still go through some sort of legal proceeding to reclaim the property and that the remedies available to him are substantially the same whether his interest be characterized as a possibility of reverter or a power of termination.
207
The distinction between the two types of classes was more evident when the classes were created, in some far-off time under different social conditions on a per-case basis as is typical under the common law. Originally those wanting to recover property physically had to enter the property and regain possession. There was then a difference between a special limitation and a condition subsequent because the owner of a possibility of reverter could commence his action for recovery of possession without the formality of entry. Today the necessity of entry is gone in all American jurisdictions.
208 Agreeing with an Oklahoma Supreme Court decision from 1944, Dunham concluded: It would appear that other courts could now well reach the conclusion of the Oklahoma court that there is really no difference between the two types of future interests.
209
The artificiality of this part of the property law ontology was growing more evident within the legal community in 1964 when Professor Edward Halbach, Jr. at the University of California reiterated that The distinction [between the two classes] is purely formalistic. It is supported neither by policy nor logic, and the sooner we are rid of it the better. Fortunately, considerable progress can now be reported:
210
Admittedly this is a premature requiem for a distinction we have already endured too long. We are yet a substantial way from being completely rid of it, but definite progress is noticeable. Even for those states and in those particular problem areas where progress has been especially slow, some examples are available of decisions and legislation upon which to pattern better methods of handling each of the types of cases for which the vested-contingent distinction has been preserved. Thus it should only be a matter of time before this meaningless and troublesome distinction will be of purely historical interest.211
Halbach's assessment is proving prophetic, although change is occurring slowly. By 1972 Professor Lawrence Waggoner bewailed that [o]nly three states currently have legislation which can properly be regarded as simplifying and improving the common law structure in any significant sense.
212 Nevertheless, legislatures have begun to recognize that a change is necessary. In 1982 California, to cite one example, abolished the class of Fee Simple Determinable, combining it into the class of Fee Simple on Condition Subsequent.213
Professor Halbach has examined the current ontology of property law in detail and found that it is in need of more extensive refactoring throughout. He points out that the current model was developed on a case-by-case basis over seven centuries, and has developed an unnecessary complexity.214 Furthermore, he claims, many of the class divisions are artificial, pointing to Fee Simple Determinable and Fee Simple on Condition Subsequent in particular. This has resulted in an ontology that presents barriers to comprehension.215
Halbach's solution is an entire formulation or refactoring of property law ontology. His resulting ontology, as expected in classical refactoring, would not produce different outcomes, but would be built upon a model that is more intuitive. [T]he same degree of flexibility in the [present ontology] can be sustained under a vastly simplified system,
he explains.216 Calling for legislative action, Halbach presents an assemblage of provisions that might be used as the nucleus of a statute fulfilling this objective.
217
Tomorrow's Ontologies
Proposals such as those by Professor Halbach are part of a larger movement towards enhancing the way law models the world. Bottom-up agile common-law modeling tendencies are being combined with the grand architectural processes of top-town domain-driven civil law systems in an attempt to marry pragmatism with correctness and provide long-lasting solutions that are nonetheless relevant and meaningful to individual fact scenarios. This tendency in the law is, as it always has been, an iterative process of refactoring metaphysical world views. The difference is that in contemporary times those individuals and organizations driving the law's evolution, from legislatures to judges to the American Law Institute, are increasingly becoming more aware of this evolutionary process and of their own role within it.
It is at this time that awareness and analysis can provide the most benefit in helping the models of the law adequately address the law's problem domains. Recognizing the common philosophical underpinnings of the law's sister discipline, computer science, can allow the actors of the legal world to leverage the ontological modeling techniques and tools developed by computer scientists to address similar ontological models used for effective information processing. Legal actors, consciously or not, are involved in a never-ending legal play in which each act reflexively modifies the script itself. In this iterative process, a greater awareness of the refactoring process with insights from a discipline that has made conscious ontological refinement a priority could prove beneficial to legal efficacy.
In some ways the meeting of minds between legal academics and computer scientists is inevitable, especially in the burgeoning fields of artificial intelligence and computer reasoning as applied to legal information systems. As the law begins to leverage information technology to a greater extent, semantic technology and symbolic encapsulations of ontologies using frameworks such as RDF combined with axiomatic reasoning will force a closer look both at the ontologies the law has implicitly produced and the processes by which these ontologies have evolved.218
Legal models have continued to evolve since Leibniz' reorganization of the civil law and Holmes' reclassification of the common law. The actors in today's legal environment continue iteratively to refactor law's ontologies—models that are increasingly relevant beyond political boundaries and across common law and civil law traditions. There is no better time to take a conscious look at the law's evolution from an ontological viewpoint, and the processes and tools developed within the information sciences for just such a task could provide welcome insights and guidance in formulating the legal world-view of tomorrow.
Endnotes
1 Oliver Wendell Holmes, Jr., The Common Law (Dover Publications 1991) (originally published 1881).
2 Edward H. Levi, An Introduction to Legal Reasoning 8-9 (The U. of Chi. Press 1949).
3 Id. at 13.
4 Id. at 18.
5 Id. at 20 (citing MacPherson v. Buick, 111 N.E. 1050 (1916)).
6 Id. at 20-21.
7 We cannot believe that the liability of a manufacturer of an automobile has any analogy to the liability of a manufacturer of
Id. at 24 (quoting Johnson v. Cadillac, 261 Fed. 878, 886 (C.C.A. 2d, 1919)).tables, chairs, pictures or mirrors hung on walls.
The analogy is rather that of a manufacturer of unwholesome food or of a poisonous drug.
8 Id. at 26 (citing Donoghue v. Stevenson, A.C. 562 (1932)).
9 See Restatement (Third) of Torts § 1 (1997): One engaged in the business of selling or otherwise distributing products who sells or distributes a defective product is subject to liability for harm to persons or property caused by the defect.
See also Id. § 2 cmt. a: Products are not generically defective merely because they are dangerous.
10 H. L. A. Hart, The Concept of Law 128 (2d. ed., Clarendon Press 1997) (originally published 1961).
11 Levi also acknowledges this: It is only folklore which holds that a statute if clearly written can be completely unambiguous and applied as intended to a specific case.
Levi, An Introduction to Legal Reasoning at 6.
12 Korzybski founded the discipline known as general semantics. Alfred Korzybski (Wikipedia Mar. 6, 2006) (available at <http://en.wikipedia.org/wiki/Alfred_Korzybski>).
13 When Georg Cantor, Gottlob Frege, and Bertrand Russell in the late 1800s founded the branch of mathematics now known as set theory, dealing with groups of related items in a logically rigorous manner using symbols, the word commonly used to describe such aggregates was not set
but class,
reflected in the English word classification.
It is no coincidence that most modern object-oriented programming languages such as Java and C++ refer to the proto-object from which object instances are derived as classes.
14 William F. Opdyke, Refactoring Object-Oriented Frameworks 10 (unpublished Ph.D. thesis, U. of Illinois 1992) (available at <http://citeseer.ist.psu.edu/opdyke92refactoring.html>).
15 Grady Booch, James Rumbaugh & Ivar Jacobson, The Unified Modeling Language User Guide 3 (Addison-Wesley 1999).
16 Id. at 6.
17 Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software 2 (Addison-Wesley 2004).
18 A model is a selectively simplified and consciously structured form of knowledge. An appropriate model makes sense of information and focuses it on a problem.
Evans, Domain-Driven Design at 3.
19 [A]nalysis is to some degree always a falsification.
Ray Monk, Bertrand Russell: The Spirit of Solitude 109 (Vintage 1997).
20 Ceci n'est pas une pipe.
Magritte (Wikipedia Mar. 6, 2006) (available at <http://en.wikipedia.org/wiki/Map-territory_relation>).
21 Id.
22 U.S. v. Hamilton, 583 F.2d 448 (1978).
23 Id. at 449.
24 Id. at 449-450.
25 Id. at 452.
26 See also Stephen M. McJohn, Intellectual Property: Examples and Explanations 15, 17 (Aspen Publishers 2003).
27 Aristotle, Categoriae, in The Basic Works of Aristotle 7 (Richard McKeon ed., Modern Library paperback ed., Random House 2001).
28 Id. at 8 (1b25).
29 Id. at 12 (3b12).
30 Id. at 13 (4a17).
31 Id. at 12 (3a22).
32 Id. at 11 (3a30).
33 Id. at 11 (2b22).
34 Id. at 8 (1b10).
35 An ontology is a specification of a conceptualization.
An ontology is an explicit specification of a conceptualization. The term is borrowed from philosophy, where an Ontology is a systematic account of Existence. For AI systems, what
Tom Gruber, What is an Ontology? (available at <http://www-ksl.stanford.edu/kst/what-is-an-ontology.html>).exists
is that which can be represented. When the knowledge of a domain is represented in a declarative formalism, the set of objects that can be represented is called the universe of discourse. This set of objects, and the describable relationships among them, are reflected in the representational vocabulary with which a knowledge-based program represents knowledge. Thus, in the context of AI, we can describe the ontology of a program by defining a set of representational terms. In such an ontology, definitions associate the names of entities in the universe of discourse (e.g., classes, relations, functions, or other objects) with human-readable text describing what the names mean, and formal axioms that constrain the interpretation and well-formed use of these terms. Formally, an ontology is the statement of a logical theory.
36 The diagramming framework used here is the Unified Modeling Language (UML), described later in this work.
37 Aristotle, De Partibus Animalium, in The Basic Works of Aristotle 643, 651 (642b10) (Richard McKeon ed., Modern Library paperback ed., Random House 2001). See also Marc Ereshefsky, The Poverty of the Linnaean Hierarchy: A Philosophical Study of Biological Taxonomy 20 (ebook ed., Cambridge U. Press 2004).
38 In this work taxonomy is used to indicate that part of an ontology restricted to a hierarchical ordering of terms without regard to properties, composition, or more complex relationships among items.
39 Aristotle, De Partibus Animalium.
40 While the author of Categoriae would have categorized himself as Animal←Man←Aristotle, under modern biological categorization he would be classified as Eukarya←Animalia←Chordata← Mammalia←Primates←Hominidae←Homo←Sapiens←Aristotle.
41 See e.g. Ereshefsky, The Poverty of the Linnaean Hierarchy.
42 Charles Darwin, On the Origin of the Species: A Facsimile of the First Edition (Harv. U. Press 2005) (originally published 1859).
43 G. Edward White, Justice Oliver Wendell Holmes: Law and the Inner Self 113 (Oxford U. Press 1993).
44 Sheldon M. Novick in introduction to Holmes, The Common Law at xv.
45 White, Justice Oliver Wendell Holmes: Law and the Inner Self at 116.
46 Oliver Wendell Holmes, Codes, and the Arrangement of the Law, in The Formative Essays of Justice Holmes: The Making of an American Legal Philosophy 77 (Frederic Rogers Kellogg ed., Greenwood Press 1984).
47 White, Justice Oliver Wendell Holmes: Law and the Inner Self at 117.
48 Holmes sought to trace legal ideas to unconscious elements implicit in the very language and institutions of the law, which he believed were evolving just as the bony skeleton of the mammal had evolved from the more primitive forms of the fish.
Sheldon M. Novick in introduction to Holmes, The Common Law at xvi.
49 Holmes, The Common Law at 77.
50 Id. at 78.
51 F. W. Maitland, The Forms of Action at Common Law: A Course of Lectures 10, 7 (Cambridge U. Press 1989) (originally published 1909).
52 So great is the ascendancy of the Law of Actions in the infancy of Courts of Justice, that substantive law has at first the look of being gradually secreted in the interstices of procedure.
Maitland, The Forms of Action at Common Law at 1 (quoting Maine, Early Law and Custom 389).
53 Id. at 2.
54 Id.
55 Id.
56 S. F. C. Milsom, A Natural History of the Common Law 30 (Colum. U. Press 2003). It should be noted that Roman law, which represented the top-down
legal structuring of the civil law rather than the bottom-up
legal evolution found in the common law, at the time had already set out ontological legal issues such as property in chattels and fault, separate from procedure. Id. at 2.
57 Maitland, The Forms of Action at Common Law at 3.
58 Id. at 5.
59 With more insight than perhaps he realizes, S. F. C. Milsom, professor emeritus of law at Cambridge University, writes: It was no more than a programming code, and nobody now supposed that it had any basis in the facts.
Milsom, A Natural History of the Common Law at 34.
60 Maitland, The Forms of Action at Common Law at 5.
61 Id. at 6.
62 Id. at 7 (emphasis added). Maitland here notes that we are only gradually obtaining
such a rational classification of causes of action.
63 John E. Cribbet, Corwin W. Johnson, Roger F. Findley & Ernest E. Smith, Property: Cases and Materials, 39 (8th ed., Foundation Press 2002).
64 Holmes, The Common Law at 82.
65 Schley v. Couch, 284 S.W.2d 333 (1955).
66 Id. at 334.
67 This was the definition used by the Supreme Court. Id. at 335.
68 Id. at 334-335.
69 Id. at 335.
70 Id. at 337-338.
71 Id. at 340.
72 Peter Stein, Roman Law in European History 8 (ebook ed., Cambridge U. Press 2004).
73 Id. at 18.
74 Id. at 19.
75 Boolean is named after British mathematician George Boole. See discussion below.
76 Stein, Roman Law in European History at 20.
77 Id. at 1.
78 Id. at 47.
79 Id. at 64.
80 Id. at 79.
81 Id. at 80.
82 Id. at 107.
83 Mary Ann Glendon, Michael Wallace Gordon & Christopher Osakwe, Comparative Legal Traditions: Text, Materials and Cases 192 (2d ed., West Group 1994).
84 Konrad Zweigert & Hein Kötz, Introduction to Comparative Law 251 (Tony Weir trans., 3d rev. ed., Clarendon Press 1998) (originally published North-Holland Pub. Co. 1977).
85 Id. at 252.
86 Id.
87 Restatement (Second) of Contracts §§ 1-5 (1979).
88 A more rigorous representation would take account of the categories Bargain
and Agreement,
as well as the distinction between a Term
of a Promise and a Term
of a Contract.
89 Zweigert et al., Introduction to Comparative Law at 270.
90 Id. at 269.
91 Id. at 271.
92 One example is the Jacquard loom of the early 1800s, which automatically translated card patterns into cloth designs.
Kenneth C. Louden, Programming Languages: Principles and Practice 31 (PWS Publishing Co. 1993).
93 The analogous stage in the evolution of law could be considered simple, pre-statute communities in which custom and human predispositions biologically hard-wired
ruled.
94 Louden, Programming Languages at 2.
95 It is no coincidence that the American Heritage Dictionary defines code
both as A system of symbols and rules used to represent instructions to a computer; a computer program
and A systematically arranged and comprehensive collection of laws,
for the two stand on the same analytic philosophical footing. American Heritage Dictionary of the English Language (4th ed., Houghton Mifflin Co. 2004) (available at <http://www.answers.com/topic/coding>).
96 Louden, Programming Languages at 2.
97 Id. at 3.
98 Because each instruction or command represented an imperative, procedural languages are sometimes called imperative languages. Louden, Programming Languages at 11. Compare Austin's command theory of the law in The Province of Jurisprudence Determined in 1832, written before the Judicature Act of 1873 abolished forms of action and the common law was firmly procedural. John Austin, The Province of Jurisprudence Determined (Cambridge U. Press 1995) (originally published 1832). See also Hart's reaction against Austin's command theory at a time when the law was more class or object-oriented. Hart, The Concept of Law at 18.
99 Matt Weisfeld, The Object-Oriented Thought Process 9 (ebook ed., Sams 2000).
100 Computer software functions and procedures are traditionally distinguished in that the former returns a value while the latter does not.
101 Mary Shaw, Abstraction Techniques in Modern Programming Languages, in Milestones in Software Evolution 139, 141 (Paul W. Oman & Ted G. Lewis ed., IEEE Computer Society Press 1990) (originally published in Oct. 1984 IEEE Software 10-26).
102 Maitland, The Forms of Action at Common Law at 68. See discussion in R. C. Van Caenegam, The Birth of the English Common Law 42-47 (2d. ed., Cambridge U. Press 1997).
103 D. L. Parnas, On the Criteria to be Used in Decomposing Systems into Modules, in Milestones in Software Evolution 27 (Paul W. Oman & Ted G. Lewis ed., IEEE Computer Society Press 1990) (originally published in 15 Communications of the ACM 12, 1053-1058 (Dec. 1972)).
104 Shaw, Abstraction Techniques in Modern Programming Languages at 140, 142.
105 Louden, Programming Languages at 37.
106 Weisfeld, The Object-Oriented Thought Process at 206.
107 A better term might have been class-oriented, although object-oriented programming languages also have objects, as the later discussion of class versus instance makes clear. Bertrand Meyer points out that objects do not represent a new concept, having been present as structures
in C; what is unique about object-oriented programming languages is the presence of the class, which is the central concept of object technology.
Bertrand Meyer, Object-Oriented Software Construction 165 (2d ed., Prentice Hall PTR 1997).
108 Louden, Programming Languages at 37.
109 Weisfeld, The Object-Oriented Thought Process at 207.
110 C was invented by Brian Kernighan and Dennis Ritchie, also at Bell Labs. Id. See also Louden, Programming Languages at 318.
111 Weisfeld, The Object-Oriented Thought Process at 207.
112 In C, C++, Java, and other related languages, ++
is the increment operator
—the symbol for the programmatic operation of adding the integer one two a value.
113 Id. at 208.
114 Aristotle, Categoriae at 9 (2a16).
115 Bruce Eckel, Thinking in Java 248 (beta ebook ed., 3d. ed., Prentice Hall 2003).
116 Aristotle, Categoriae at 8 (1b10).
117 Id. at 11 (2b28).
118 Bill Venners, Composition versus Inheritance: A Comparative Look at Two Fundamental Ways to Relate Classes (available at <http://www.artima.com/designtechniques/compoinh.html>) (originally published Oct. 1998 JavaWorld).
119 The Location type is assumed to have been defined using a Java 1.5 enumeration: enum Location{aquatic, terrestrial};
120 Louden, Programming Languages at 299.
121 The Unified Modeling Language (UML) is a general-purpose visual modeling language that is used to specify, visualize, construct, and document the artifacts of a software system.
Grady Booch, James Rumbaugh & Ivar Jacobson, The Unified Modeling Language Reference Manual, 3 (Addison-Wesley 1999). See generally UML™ Resource Page (Object Management Group Jan. 4, 2006) (available at <http://www.uml.org/>).
122 Martin Fowler, a well-known writer on object-oriented programming techniques: Graphical design notations have been with us for a while. For me, their primary value is in communication and understanding. A good diagram can often help communicate ideas about a design, particularly when you want to avoid a lot of details.
Martin Fowler, UML Distilled: A Brief Guide to the Standard Object Modeling Language xxvi (3d ed., Addison-Wesley 2004).
123 Id. at 7.
124 See generally Object Management Group (Object Management Group Mar. 6, 2006) (available at <http://www.omg.org/>).
125 Booch et al., The Unified Modeling Language Reference Manual at 6.
126 The near-simultaneous introduction of Java, an updated object-oriented programming language, and the creation of the UML, a standardized notation for modeling objects, helped usher in the current emphasis on domain-driven modeling.
127 The Unified Modeling Language (UML) is a family of graphical notations, backed by single meta-model, that help in describing and designing software systems, particularly software systems built using the object-oriented (OO) style.
Fowler, UML Distilled at 1.
128 Recall Aristotle's discussion of whole/part relationships in Aristotle, Categoriae at 11 (3a30).
129 Always remember that the model is not the diagram. The diagram's purpose is to help communicate and explain the model.
Evans, Domain-Driven Design at 37.
130 Evans, Domain-Driven Design.
131 Id. at xix. Evans notes that Leading software designers have recognized domain modeling and design as critical topics for at least 20 years, yet surprisingly little has been written about what needs to be done or how to do it.
Id.
132 Opdyke, Refactoring Object-Oriented Frameworks.
133 Id. at iii.
134 Refactoring does not change the behavior of a program; that is, if a program is called twice (before and after refactoring) with the same set of inputs, the resulting set of output values will be the same.
Opdyke, Refactoring Object-Oriented Frameworks at 2.
135 Holmes, The Common Law at 82.
136 Opdyke, Refactoring Object-Oriented Frameworks at iii.
137 Stein, Roman Law in European History at 18.
138 Opdyke, Refactoring Object-Oriented Frameworks at 13.
139 Aristotle, Categoriae at 11 (3a23).
140 Opdyke, Refactoring Object-Oriented Frameworks at 18.
141 Martin Fowler, Refactoring: Improving the Design of Existing Code (Addison-Wesley 1999).
142 Joshua Kerievsky, Refactoring to Patterns (Addison-Wesley 2005).
143 Meyer, Object-Oriented Software Construction at 726.
144 Ivar Jacobson, Grady Booch & James Rumbaugh, The Unified Software Development Process 450 (Addison-Wesley 1999).
145 Walker Royce, Software Project Management: A Unified Framework 8 (Addison-Wesley 1998) (emphasis removed).
146 Kent Beck, Extreme Programming Explained: Embrace Change 21 (Addison Wesley 2000).
147 Id. at 54.
148 Id. at 30.
149 Matt Stephens & Doug Rosenberg, Extreme Programming Refactored: The Case against XP (ebook ed., Apress 2003).
150 Id. at 22.
151 Id. at 62.
152 Jacobson et al., The Unified Software Development Process at 6.
153 Id. at 7.
154 Fowler, UML Distilled at 25.
155 The term metaphysics is a later term given to the section of Aristotle's work dealing primarily with this subject. Michael J. Loux, Metaphysics: A Contemporary Introduction 2 (2d. ed., Routledge 2004) (originally published 1998).
156 Id. at 3-4.
157 Id. at 16.
158 Id. at 17-18.
159 Introduction to Austin, The Province of Jurisprudence Determined at viii. See generally Jeremy Bentham, An Introduction to the Principles of Morals and Legislation (J. H. Burns & H. L. A. Hart ed., Oxford U. Press 1996) (originally published 1970).
160 H. L. A. Hart, Bentham's Principle of Utility and Theory of Penal Law, in An Introduction to the Principles of Morals and Legislation, lxxxiii (J. H. Burns & H. L. A. Hart ed., Oxford U. Press 1996) (originally published 1970).
161 Austin, The Province of Jurisprudence Determined.
162 Frederic Rogers Kellog in Oliver Wendell Holmes, The Formative Essays of Justice Holmes: The Making of an American Legal Philosophy 6 (Frederic Rogers Kellogg ed., Greenwood Press 1984).
163 Martin Davis, The Universal Computer: The Road from Leibniz to Turing 7 (W. W. Norton & Co. 2000).
164 Id. at 5.
165 Id. at 27.
166 Id. at 5.
167 Id. at 40.
168 Id. at 34.
169 Id. at 35.
170 Id. at 39.
171 The boolean
value used in the previous example of Gaius' reformulation of the civil law is one example use of Boole's concept.
172 Gottlob Frege, Begriffsschrift, in The Frege Reader 47 (Michael Beaney ed., Blackwell Publishing 2003) (originally published 1879).
173 Martin, The Universal Computer at 48.
174 Bertrand Russell's father had been a strong supporter of Jeremy Bentham's political philosophy. Monk, Bertrand Russell: The Spirit of Solitude at 7.
175 See Alfred North Whitehead & Bertrand Russell, Principia Mathematica to *56 (Cambridge at the U. Press 1962) (originally published 1913).
176 Bertrand Russell, A History of Western Philosophy 830 (Touchtone ed., Simon & Schuster 1972) (originally published 1945).
177 Ernest Nagel & James R. Newman, Gödel's Proof (rev. ed., New York U. Press 2001).
178 Martin, The Universal Computer at 180.
179 Id. at 192.
180 See Von Neumann architecture (Wikipedia Mar. 7, 2006) (available at <http://en.wikipedia.org/wiki/Von_Neumann_architecture>).
181 See Monk, Bertrand Russell: The Spirit of Solitude at 237. See generally Monk, Bertrand Russell: The Spirit of Solitude and Ray Monk, Bertrand Russell: The Ghost of Madness 1921-1970 (Vintage 2001).
182 See generally William G. Lycan, Philosophy of Language: A Contemporary Introduction (Routledge 2002).
183 Ludwig Wittgenstein, Philosophical Investigations § 67, 32e (G. E. M. Anscombe trans., 3d ed., Prentice Hall 1958) (originally published Macmilliam Publishing Co. 1953).
184 Hart, The Concept of Law at 128.
185 Brian Bix, Law, Language, and Legal Determinacy 7 (Clarendon Press 2003).
186 Hart, The Concept of Law at 280, 297.
187 J. L. Austin, How to Do Things with Words 7 (J. O. Urmson & Marina Sbisà eds., 2d. ed., Harv. U. Press 2001) (originally published 1962).
188 The author made small contributions to the RDF Primer module of the RDF specification. RDF Primer (Frank Manola & Eric Miller eds., W3C Feb. 10, 2004) (available at <http://www.w3.org/TR/rdf-primer/>).
189 World Wide Web Consortium (W3C Mar. 3, 2006) (available at <http://www.w3.org/>).
190 See generally OWL Web Ontology Language Overview (W3C Feb. 10, 2004) (available at <http://www.w3.org/TR/owl-features/>).
191 See generally Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005).
192 Oscar Corcho, Mariano Fernández-López, Asunción Gómez-Pérez & Angel López-Cima, Building Legal Ontologies with METHONTOLOGY and WebODE, in Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications 142, 147 (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005) (diagram simplified and converted to UML).
193 Although a case in contract law, for example, may revolve around a physical document, the ontology of property law is built on a framework of abstract ontological concepts such as offer
, acceptance
, and agreement
that do not necessarily represent physical objects.
194 Cornelius J. Moynihan & Sheldon F. Kurtz, Introduction to the Law of Real Property 2 (Thomson West 2005).
195 All persons having an intermediate place in this structure held the land in a dual capacity—they were tenants of those above them and lords (mesne lords) with respect to those holding under them.
Id. at 9.
196 Id.
197 See generally Id.
198 If tenure by knight service had been abolished in 1300, the kings of the subsequent ages would have been deprived of the large revenue that they drew from wardships, marriages and so forth; really they would have lost little else.
Id. at 11 (quoting 1 Pollock and Maitland, History of English Law 276 (2d ed., 1898)).
199 Id. at 33.
200 Id. at 128.
201 Id. at 50-51.
202 Id. at 52.
203 Id. at iii.
204 The class of Dower, for instance, was established in an agrarian society to provide social and economic security for widows. Because of increasing rights of women in property ownership and opportunities in employment, most states abolished this class in the Twentieth Century. Id. at 72.
205 Allison Dunham, Possibility of Reverter and Powers of Termination—Fraternal or Identical Twins?, 20 U. Chi. L. Rev. 215 (Winter 1953).
206 Meyer, Object-Oriented Software Construction at 726.
207 Dunham, Possibility of Reverter and Powers of Termination—Fraternal or Identical Twins? at 216.
208 Id. at 230.
209 Id. at 222, 234.
210 Edward C. Halbach, Jr., Vested and Contingent Remainders: A Premature Requiem for Distinctions between Conditions Precedent and Subsequent, in Perspectives of Law: Essays for Austin Wakeman Scott 152 (Roscoe Pound, Erwin N. Griswold & Arthur E. Sutherland eds., Little, Brown & Co. 1964).
211 Id. at 172.
212 Lawrence W. Waggoner, Reformulating the Structure of Estates: A Proposal for Legislative Action, 85 Harv. L. Rev. 729, 733 (February 1972).
213 Cal. Civ. Code Ann. § 885.020 (West Supp. 2006).
214 The Roman Law, it will be remembered, which has developed property law in more of a top-down fashion, has developed a more elegant model of property without, for example, a distinction between the law of land and the law of movables. Cribbet et al., Property: Cases and Materials at 39.
215 Waggoner, Reformulating the Structure of Estates at 729-732.
216 Id. at 731.
217 Id. at 766.
218 Josep Aguiló-Regla, for instance, discusses how conceptions of the law as well as information technology representations of those ontologies have changed over the last few decades. Josep Aguiló-Regla, Introduction: Legal Informatics and the Conceptions of the Law, in Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications 18 (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005) .
Works Cited
- Alfred Korzybski (Wikipedia Mar. 6, 2006) (available at <http://en.wikipedia.org/wiki/Alfred_Korzybski>).
- Josep Aguiló-Regla, Introduction: Legal Informatics and the Conceptions of the Law, in Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications 18 (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005).
- American Heritage Dictionary of the English Language (4th ed., Houghton Mifflin Co. 2004).
- Aristotle, Categoriae, in The Basic Works of Aristotle 7 (Richard McKeon ed., Modern Library paperback ed., Random House 2001).
- Aristotle, De Partibus Animalium, in The Basic Works of Aristotle 643 (Richard McKeon ed., Modern Library paperback ed., Random House 2001).
- J. L. Austin, How to Do Things with Words (J. O. Urmson & Marina Sbisà eds., 2d. ed., Harv. U. Press 2001) (originally published 1962).
- John Austin, The Province of Jurisprudence Determined (Cambridge U. Press 1995) (originally published 1832).
- Kent Beck, Extreme Programming Explained: Embrace Change (Addison Wesley 2000).
- Jeremy Bentham, An Introduction to the Principles of Morals and Legislation (J. H. Burns & H. L. A. Hart ed., Oxford U. Press 1996) (originally published 1970).
- Brian Bix, Law, Language, and Legal Determinacy (Clarendon Press 2003) (originally published 1993).
- Grady Booch, James Rumbaugh & Ivar Jacobson, The Unified Modeling Language Reference Manual (Addison-Wesley 1999).
- Grady Booch, James Rumbaugh & Ivar Jacobson, The Unified Modeling Language User Guide (Addison-Wesley 1999).
- Cal. Civ. Code Ann. § 885.020 (West Supp. 2006).
- R. C. Van Caenegam, The Birth of the English Common Law (2d. ed., Cambridge U. Press 1997) (originally published 1973).
- Oscar Corcho, Mariano Fernández-López, Asunción Gómez-Pérez & Angel López-Cima, Building Legal Ontologies with METHONTOLOGY and WebODE, in Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications 142 (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005).
- John E. Cribbet, Corwin W. Johnson, Roger F. Findley & Ernest E. Smith, Property: Cases and Materials (8th ed., Foundation Press 2002).
- Charles Darwin, On the Origin of the Species: A Facsimile of the First Edition (Harv. U. Press 2005) (originally published 1859).
- Martin Davis, The Universal Computer: The Road from Leibniz to Turing (W. W. Norton & Co. 2000).
- Donoghue v. Stevenson, A.C. 562 (1932).
- Allison Dunham, Possibility of Reverter and Powers of Termination—Fraternal or Identical Twins?, 20 U. Chi. L. Rev. 215 (Winter 1953).
- Bruce Eckel, Thinking in Java (beta ebook ed., 3d. ed., Prentice Hall 2003).
- Marc Ereshefsky, The Poverty of the Linnaean Hierarchy: A Philosophical Study of Biological Taxonomy (ebook ed., Cambridge U. Press 2004).
- Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software (Addison-Wesley 2004).
- Martin Fowler, Refactoring: Improving the Design of Existing Code (Addison-Wesley 1999).
- Martin Fowler, UML Distilled: A Brief Guide to the Standard Object Modeling Language (3d ed., Addison-Wesley 2004).
- Gottlob Frege, Begriffsschrift, in The Frege Reader 47 (Michael Beaney ed., Blackwell Publishing 2003) (originally published 1879).
- Mary Ann Glendon, Michael Wallace Gordon & Christopher Osakwe, Comparative Legal Traditions: Text, Materials and Cases (2d ed., West Group 1994).
- Tom Gruber, What is an Ontology? (available at <http://www-ksl.stanford.edu/kst/what-is-an-ontology.html>).
- Edward C. Halbach, Jr., Vested and Contingent Remainders: A Premature Requiem for Distinctions between Conditions Precedent and Subsequent, in Perspectives of Law: Essays for Austin Wakeman Scott 152 (Roscoe Pound, Erwin N. Griswold & Arthur E. Sutherland eds., Little, Brown & Co. 1964).
- H. L. A. Hart, Bentham's Principle of Utility and Theory of Penal Law, in An Introduction to the Principles of Morals and Legislation (J. H. Burns & H. L. A. Hart ed., Oxford U. Press 1996) (originally published 1970).
- H. L. A. Hart, The Concept of Law (2d. ed., Clarendon Press 1997) (originally published 1961).
- Oliver Wendell Holmes, Codes, and the Arrangement of the Law, in The Formative Essays of Justice Holmes: The Making of an American Legal Philosophy 77 (Frederic Rogers Kellogg ed., Greenwood Press 1984).
- Oliver Wendell Holmes, Jr., The Common Law (Dover Publications 1991) (originally published 1881).
- Ivar Jacobson, Grady Booch & James Rumbaugh, The Unified Software Development Process (Addison-Wesley 1999).
- Johnson v. Cadillac, 261 Fed. 878 (C.C.A. 2d, 1919).
- Joshua Kerievsky, Refactoring to Patterns (Addison-Wesley 2005).
- Law and the Semantic Web: Legal Ontologies, Methodologies, Legal Information Retrieval, and Applications (V. Richard Benjamins, Pompeu Casanovas, Joost Breuker & Aldo Gangemi eds, Springer 2005).
- Edward H. Levi, An Introduction to Legal Reasoning (The U. of Chi. Press 1949).
- Kenneth C. Louden, Programming Languages: Principles and Practice (PWS Publishing Co. 1993).
- Michael J. Loux, Metaphysics: A Contemporary Introduction (2d. ed., Routledge 2004) (originally published 1998).
- William G. Lycan, Philosophy of Language: A Contemporary Introduction (Routledge 2002).
- Stephen M. McJohn, Intellectual Property: Examples and Explanations (Aspen Publishers 2003).
- MacPherson v. Buick, 111 N.E. 1050 (1916).
- Magritte (Wikipedia Mar. 6, 2006) (available at <http://en.wikipedia.org/wiki/Map-territory_relation>).
- F. W. Maitland, The Forms of Action at Common Law: A Course of Lectures (Cambridge U. Press 1989) (originally published 1909).
- Bertrand Meyer, Object-Oriented Software Construction (2d ed., Prentice Hall PTR 1997).
- S. F. C. Milsom, A Natural History of the Common Law (Colum. U. Press 2003).
- Ray Monk, Bertrand Russell: The Ghost of Madness 1921-1970 (Vintage 2001).
- Ray Monk, Bertrand Russell: The Spirit of Solitude (Vintage 1997).
- Cornelius J. Moynihan & Sheldon F. Kurtz, Introduction to the Law of Real Property (Thomson West 2005).
- Ernest Nagel & James R. Newman, Gödel's Proof (rev. ed., New York U. Press 2001).
- Object Management Group (Object Management Group Mar. 6, 2006) (available at <http://www.omg.org/>).
- William F. Opdyke, Refactoring Object-Oriented Frameworks (unpublished Ph.D. thesis, U. of Illinois 1992) (available at <http://citeseer.ist.psu.edu/opdyke92refactoring.html>).
- OWL Web Ontology Language Overview (W3C Feb. 10, 2004) (available at <http://www.w3.org/TR/owl-features/>).
- D. L. Parnas, On the Criteria to be Used in Decomposing Systems into Modules, in Milestones in Software Evolution 27 (Paul W. Oman & Ted G. Lewis ed., IEEE Computer Society Press 1990) (originally published in 15 Communications of the ACM 12, 1053-1058 (Dec. 1972)).
- RDF Primer (Frank Manola & Eric Miller eds., W3C Feb. 10, 2004) (available at <http://www.w3.org/TR/rdf-primer/>).
- Restatement (Second) of Contracts (1979).
- Restatement (Third) of Torts (1997).
- Walker Royce, Software Project Management: A Unified Framework (Addison-Wesley 1998).
- Bertrand Russell, A History of Western Philosophy (Touchtone ed., Simon & Schuster 1972) (originally published 1945).
- Schley v. Couch, 284 S.W.2d 333 (1955).
- Mary Shaw, Abstraction Techniques in Modern Programming Languages, in Milestones in Software Evolution 139 (Paul W. Oman & Ted G. Lewis ed., IEEE Computer Society Press 1990) (originally published in Oct. 1984 IEEE Software 10-26).
- Peter Stein, Roman Law in European History (ebook ed., Cambridge U. Press 2004).
- Matt Stephens & Doug Rosenberg, Extreme Programming Refactored: The Case against XP (ebook ed., Apress 2003).
- UML™ Resource Page (Object Management Group Jan. 4, 2006) (available at <http://www.uml.org/>).
- U.S. v. Hamilton, 583 F.2d 448 (1978).
- Bill Venners, Composition versus Inheritance: A Comparative Look at Two Fundamental Ways to Relate Classes (available at <http://www.artima.com/designtechniques/compoinh.html>) (originally published Oct. 1998 JavaWorld).
- Von Neumann architecture (Wikipedia Mar. 7, 2006) (available at <http://en.wikipedia.org/wiki/Von_Neumann_architecture>).
- Lawrence W. Waggoner, Reformulating the Structure of Estates: A Proposal for Legislative Action, 85 Harv. L. Rev. 729 (February 1972).
- Matt Weisfeld, The Object-Oriented Thought Process (ebook ed., Sams 2000).
- G. Edward White, Justice Oliver Wendell Holmes: Law and the Inner Self (Oxford U. Press 1993).
- Alfred North Whitehead & Bertrand Russell, Principia Mathematica to *56 (Cambridge at the U. Press 1962) (originally published 1913).
- Ludwig Wittgenstein, Philosophical Investigations (G. E. M. Anscombe trans., 3d ed., Prentice Hall 1958) (originally published Macmilliam Publishing Co. 1953).
- World Wide Web Consortium (W3C Mar. 3, 2006) (available at <http://www.w3.org/>).
- Konrad Zweigert & Hein Kötz, Introduction to Comparative Law (Tony Weir trans., 3d rev. ed., Clarendon Press 1998) (originally published North-Holland Pub. Co. 1977).
Last Edited 2012-02-06